Scrape Dokumentasi FilamentPHP 5.x — Menggunakan BeautifulSoup4 dan Markdownify
Di https://filamentphp.com/docs/5.x/, buka submenu yang tertutup agar tampil semua di layar.
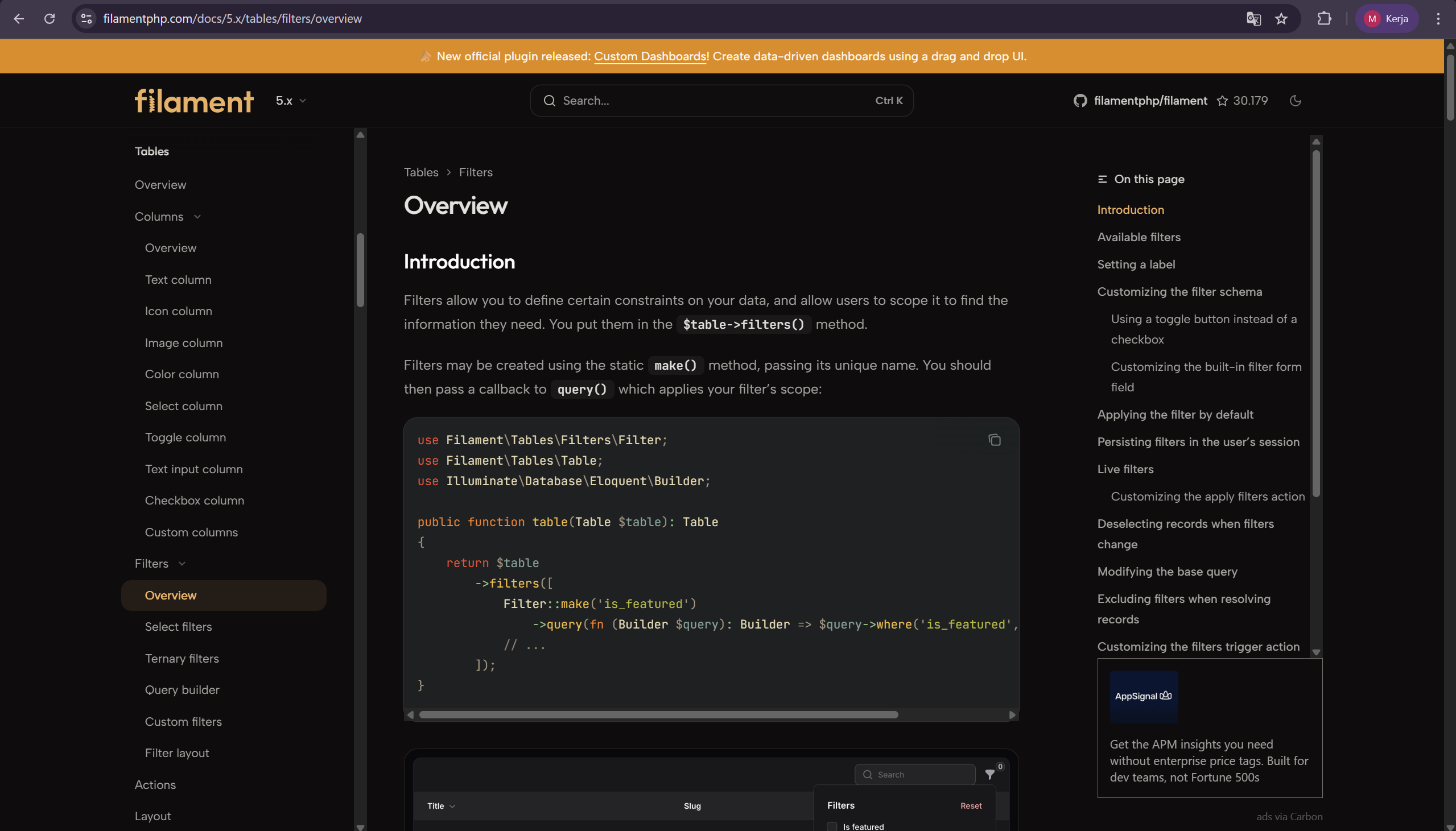
Inspect element bagian navbar dan copy-paste elemennya, lalu disimpan dalam file bernama FilamentPHP5DocsSidebar.html. Contoh element saat snippet ini dibuat: FilamentPHP5DocsSidebar.html
Ini dimasukkan dan dijalankan dalam satu folder.
File filament_doc_builder.py:
import os
import time
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify as md
from urllib.parse import urljoin, urlparse
# Configuration
SIDEBAR_FILE = 'FilamentPHP5DocsSidebar.html'
BASE_URL = 'https://filamentphp.com'
OUTPUT_MD = 'FilamentPHP_5_DocBook.md'
ASSETS_DIR = 'filament_assets'
# Create assets directory if it doesn't exist
if not os.path.exists(ASSETS_DIR):
os.makedirs(ASSETS_DIR)
def get_links_from_sidebar():
"""Extracts all documentation links from the provided sidebar HTML."""
if not os.path.exists(SIDEBAR_FILE):
print(f"Error: {SIDEBAR_FILE} not found.")
return []
with open(SIDEBAR_FILE, 'r', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'html.parser')
links = []
for a_tag in soup.find_all('a', href=True):
href = a_tag['href']
if '/docs/5.x/' in href:
title = a_tag.get_text(strip=True)
full_url = urljoin(BASE_URL, href)
if not any(link['url'] == full_url for link in links):
links.append({'title': title, 'url': full_url})
return links
def download_and_localize_image(img_url):
"""Downloads an image and returns the local relative path."""
try:
# Clean the URL
parsed_url = urlparse(img_url)
# Create a filename based on the path to avoid collisions
filename = parsed_url.path.strip('/').replace('/', '_')
if not filename.lower().endswith(('.png', '.jpg', '.jpeg', '.svg', '.gif')):
filename += ".jpg"
local_path = os.path.join(ASSETS_DIR, filename)
# Only download if we haven't already
if not os.path.exists(local_path):
img_data = requests.get(img_url, timeout=10).content
with open(local_path, 'wb') as handler:
handler.write(img_data)
return local_path
except Exception as e:
print(f" ! Failed to download image {img_url}: {e}")
return img_url
def build_doc_book():
links = get_links_from_sidebar()
print(f"Found {len(links)} pages. Starting compilation...")
with open(OUTPUT_MD, 'w', encoding='utf-8') as book:
book.write(f"# FilamentPHP 5.x Reference Book\n\n")
book.write(f"> Compiled on {time.ctime()}\n\n")
for i, item in enumerate(links):
print(f"[{i+1}/{len(links)}] Processing: {item['title']}")
try:
res = requests.get(item['url'], headers={'User-Agent': 'Mozilla/5.0'})
res.raise_for_status()
soup = BeautifulSoup(res.text, 'html.parser')
# Target the main content area
content = soup.find('main') or soup.find(class_='prose')
if not content:
print(f" ! Content not found for {item['title']}")
continue
# 1. CLEANUP: Remove duplicate Dark Mode images
# Filament hides these in spans with data-rmiz-content="not-found"
for dark_span in content.find_all('span', {'data-rmiz-content': 'not-found'}):
dark_span.decompose()
# 2. IMAGES: Download and fix paths
for img in content.find_all('img'):
src = img.get('src')
if src:
full_img_url = urljoin(BASE_URL, src)
# Download and get local path
local_img_path = download_and_localize_image(full_img_url)
img['src'] = local_img_path
# 3. LINKS: Ensure all internal links remain absolute so they work in MD
for a in content.find_all('a', href=True):
if a['href'].startswith('/'):
a['href'] = urljoin(BASE_URL, a['href'])
# 4. CONVERT TO MARKDOWN
# We use ATX headers (###) to keep the structure clean
markdown_text = md(str(content), heading_style="ATX")
# Write to book
book.write(f"\n\n---\n")
book.write(f"# {item['title']}\n")
book.write(f"**URL:** {item['url']}\n\n")
book.write(markdown_text)
book.write(f"\n\n")
except Exception as e:
print(f" ! Error processing {item['url']}: {e}")
# Pause to be respectful to the server
time.sleep(1)
print(f"\nSuccess! Your book is ready: {OUTPUT_MD}")
print(f"All images are saved in: {ASSETS_DIR}")
if __name__ == "__main__":
build_doc_book()
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ pip install requests beautifulsoup4 markdownify
(venv) $ python3 filament_doc_builder.py
Screenshot: